用 165 美元训出跨 25 个物种的 mRNA 模型,这事真正打到的是生物 AI 的成本线
OpenMed 把 mRNA 优化这件事从“高门槛生物工程”往“可复用的开源流水线”推了一步。更值得注意的不是单个指标,而是他们证明了跨物种、低成本、可复现实验这三件事可以同时成立。
来源参考: Hugging Face
很多人一提生物 AI,脑子里先跳出来的还是 AlphaFold 那种“超级模型 + 超大算力 + 超长周期”的叙事。但 OpenMed 这篇更有意思,因为它讲的不是神话,而是一条真的能被小团队跑起来的生物模型流水线。
它们做的事情,简单说有三步:先预测蛋白质结构,再设计可能折叠成目标结构的氨基酸序列,最后把这些蛋白序列翻成适合特定物种表达的 mRNA/DNA codon 序列。前两步很多人熟,分别接 ESMFold 和 ProteinMPNN。真正花力气的,是第三步——codon optimization(密码子优化)。
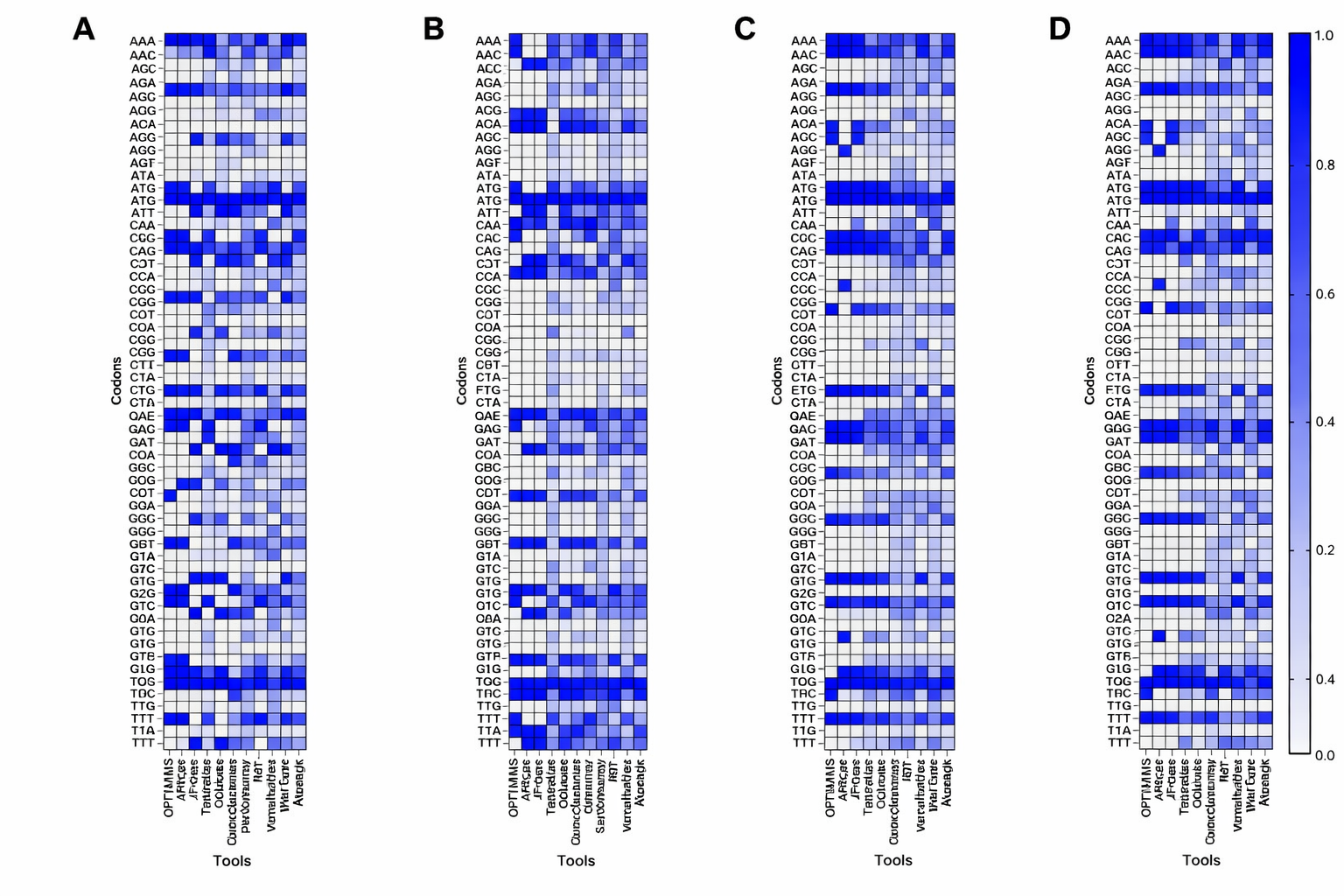
这一步为什么重要?因为同一条蛋白质,可以由天文数量级的不同 DNA/mRNA 序列来编码。蛋白本身一样,不代表表达效率一样。不同密码子的选择,会影响翻译速度、mRNA 稳定性、折叠过程,甚至免疫识别。说得更直白一点:序列写对了,药能做出来;写错了,可能表达量直接差两个数量级。
传统做法靠的是频率表,比如看宿主细胞最偏爱哪些密码子,然后尽量往那个方向替换。这种办法不算错,但很粗糙,因为它默认每个位置都是独立决策,几乎不理解上下文。OpenMed 这次的意思很明确:不要再把密码子优化当静态表查询问题,而要把它当成一个序列建模问题。也就是让模型去学“生物系统真正偏好什么样的上下文组合”。
他们最后跑出来的最好版本,是一个叫 CodonRoBERTa-large-v2 的模型。最扎眼的结果不是参数多大,而是几个很现实的数字:在单物种实验里,perplexity 做到 4.10,CAI Spearman 相关性 0.404;然后再往上扩,把数据扩展到 25 个物种、38 万多条编码序列,训练出 4 个生产级模型,总成本只用了 55 个 GPU 小时,折算下来大约 165 美元。
这个数字很重要,因为它把一件原本容易被讲成“只有大药厂和顶级实验室才能玩”的事,拉回到了更接近开源工程的语境里。不是说 165 美元就能做出新药,而是说生物序列层的基础模型实验,正在从资本密集型问题,变成方法论和数据工程问题。 这两个世界的门槛完全不一样。
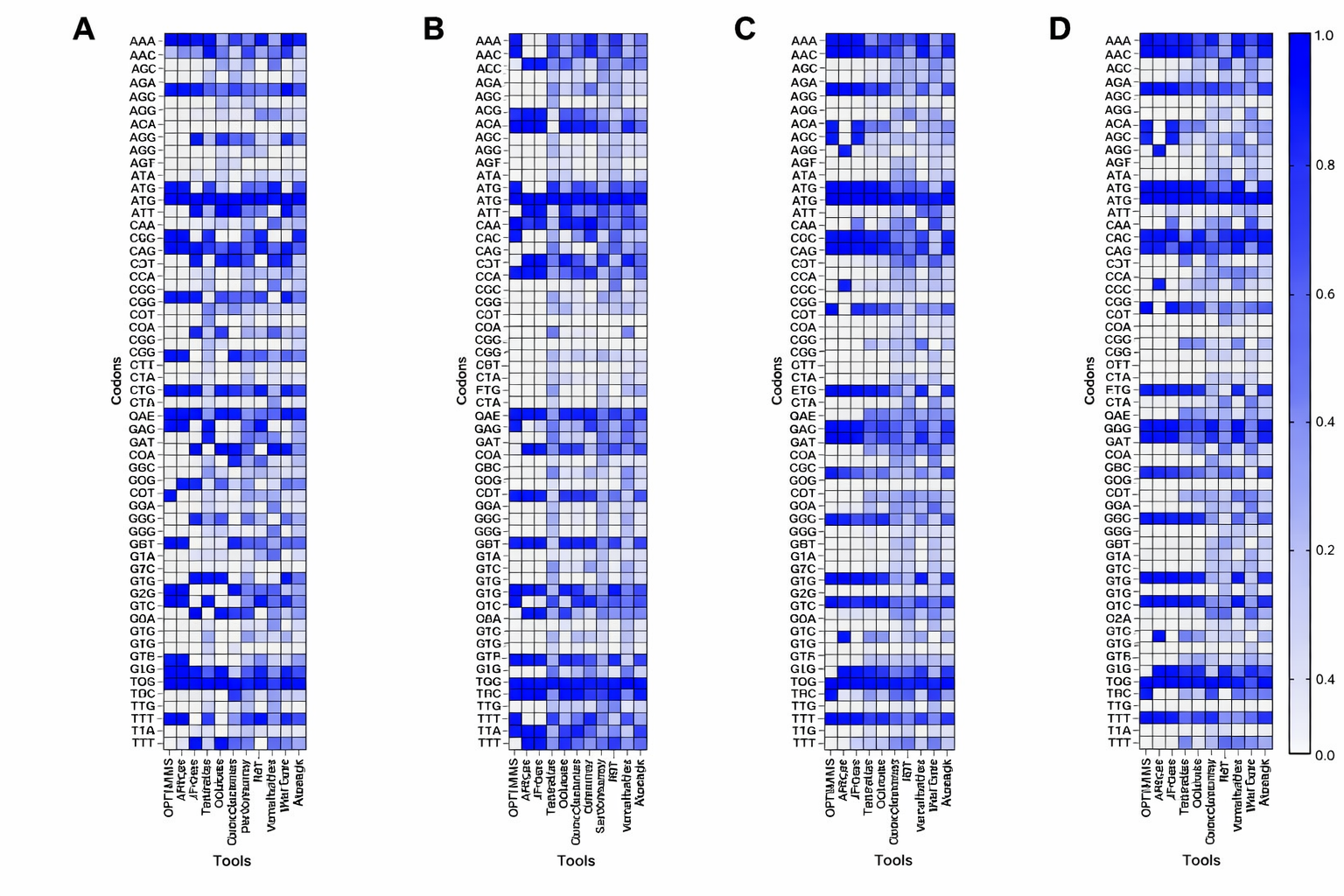
我觉得这篇里最有价值的判断,不是“RoBERTa 打赢了 ModernBERT”,虽然这个结论也挺有意思。真正值得记住的是另一点:在生物序列建模里,NLP 世界里最新、最潮的架构,不一定天然更好。 OpenMed 发现 ModernBERT 明显不如 RoBERTa,原因很可能就是 NLP 预训练里学到的偏置,反而妨碍了它理解 codon 这种完全不同的统计结构。换句话说,生物不是自然语言的一个小分支,硬把 NLP 经验平移过来,常常会踩坑。
他们还有一个很实用的发现:同样的模型架构,光靠调学习率和 warmup,就能让“模型指标看起来不错”和“模型真的更符合生物规律”之间拉开巨大差距。v1 和 v2 的 perplexity 差别不大,但生物相关性直接从 0.025 拉到 0.404。这其实也在提醒所有做 AI for Science 的团队:loss 不是全部,领域指标才决定你的模型到底有没有用。
从产业角度看,这件事的价值不只是论文式结果,而是它把一条更完整的开源生物 AI 路径拼出来了:结构预测、序列设计、密码子优化,再到跨物种条件建模。今天它离真正的湿实验闭环和药物开发还远,但它已经足够说明一个趋势——未来生物 AI 的竞争,不只是谁有更大的 foundation model,也是谁能把工具链、数据清洗、评测指标和下游工作流真正串起来。
当然,不确定性也很明显。首先,这类模型现在更多还是在“生物合理性”层面逼近,而不是在真实实验表达量、免疫反应和体内表现上完成闭环验证。其次,跨 25 个物种很有吸引力,但不同宿主系统里的表达机制、调控逻辑和工程约束远比单个序列复杂。再往前走,真正决定这类系统值不值钱的,不会只是模型 checkpoint,而是它能不能和实验、制造、法规链条接上。
但就算把这些保留意见都算进去,我还是会把这篇看成一个挺明确的信号:开源生物 AI 开始进入“能搭流水线、能谈成本、能讨论生产可用性”的阶段了。 这比再多一个炫技 demo 更值得注意,因为它离现实世界近得多。