当 Autoresearch 拿到 16 张 GPU,Agent 做研究这件事开始变味了
SkyPilot 团队把 Claude Code 接到 Karpathy 的 autoresearch 项目上,再给它 16 张 GPU 和一个 Kubernetes 集群。结果不只是实验跑得更快,而是 agent 的研究方法本身变了:从串行试错,变成并行搜索、分层验证,甚至学会了按 H100 和 H200 的差异来分配实验。
来源参考: SkyPilot Blog
我最近看到这篇实验记录,最大的感受不是“Claude Code 又变强了”,而是 agent 一旦从单卡试验台走进 GPU 集群,它做的就不再只是自动化,而更像研究流程重组。
SkyPilot 团队做了一件很直接的事:把 Claude Code 指向 Karpathy 的 autoresearch,再给它 16 张 GPU 和一个 Kubernetes 集群,让它连续跑 8 小时。结果是它总共提交了大约 910 个实验,把 val_bpb 从 1.003 压到 0.974,按文中的口径,相对 baseline 提升了 2.87%。
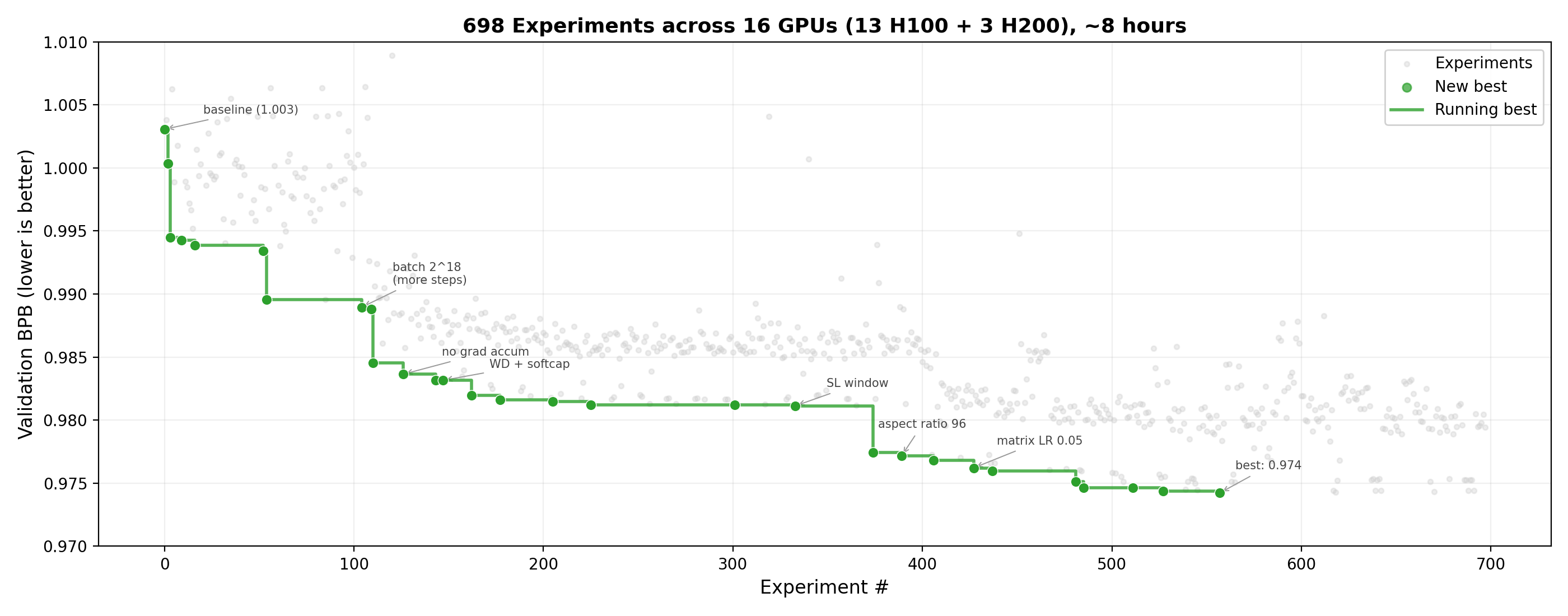
这个数字当然不难写进标题,但我觉得真正值得看的是另一层:并行算力不是单纯把等待时间缩短,而是把 agent 的搜索策略整个改写了。
在单卡模式下,autoresearch 本质上很像一个老老实实的循环:改 train.py,跑 5 分钟训练,看验证结果,再决定下一个实验。这个流程的问题不在于它不能工作,而在于它太像顺着山坡摸索。一次只能试一个点,看到局部变好就继续往前挪,很容易掉进局部最优,也很难迅速看清多个参数之间的联动关系。
可一旦资源变成 16 张 GPU,事情就完全不是一个量级了。agent 不需要再按顺序猜,它可以一波同时发出 10 到 13 个实验,把不同的学习率、weight decay、batch size,甚至不同模型宽度一起试掉。原来要花半小时排队验证的假设组合,现在 5 分钟就能看出趋势。
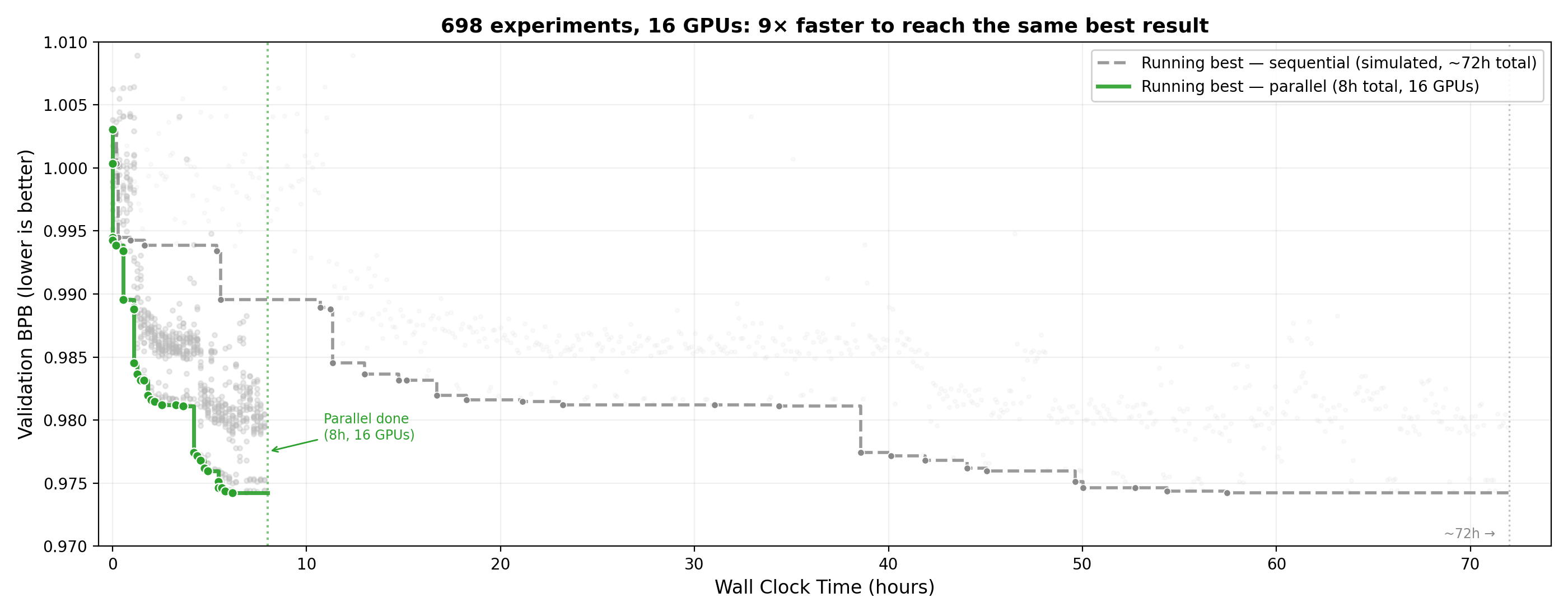
按照 SkyPilot 的测试,这套并行版 autoresearch 在大约 8 小时里达到了串行基线 72 小时左右才能摸到的最好验证损失,墙钟时间接近 9 倍缩短。如果只把这个理解成“加卡提速”,其实有点低估了这件事。更准确的说法是,agent 开始有能力用并行性换信息密度。
这也是文中最有意思的一段:它不是只会把更多任务扔出去,而是逐渐学会了怎么组织这些任务。
比如在模型宽度这件事上,它一口气测试了多个 aspect ratio,从 48 一直扫到 112。结果发现,单纯把模型做宽,比前面大量超参数微调都更有效,最佳点落在 AR=96,对应 model_dim=768。如果是串行搜索,这个发现很可能会来得很慢。因为你一次只试一个宽度,中间任何一个不够显著的结果,都可能让你提前放弃方向。但并行搜索的好处,就是它能在一轮里直接看到整体趋势,而不是被单点噪声牵着走。
它后面甚至还自己摸清了异构硬件的用法。集群里既有 H100,也有 H200,作者并没有提前告诉 agent 两者的差异。可跑了几轮之后,它发现同样的配置在 H200 上结果更好,原因不是玄学,而是 H200 在同样的 5 分钟预算里能多跑出大约 9% 的 step。于是它自然长出了一套分层策略:先用 H100 大规模筛选想法,再把优胜配置送到 H200 上做确认。
这一段很关键。因为它说明 agent 不是只在执行脚本,而是在根据环境反馈重写实验制度。你可以把它理解成一个很朴素的研究管理能力:便宜算力负责铺面,稀缺算力负责复核。这个动作人类研究者当然也会做,但今天它开始能在 agent 身上自发生长了。
SkyPilot 在这里扮演的角色也值得注意。它不是直接替 agent 做研究,而是给了一个足够抽象、又足够可操作的基础设施接口。通过一个 experiment.yaml,agent 可以自己发起任务、复用集群、看日志、继续排队执行:
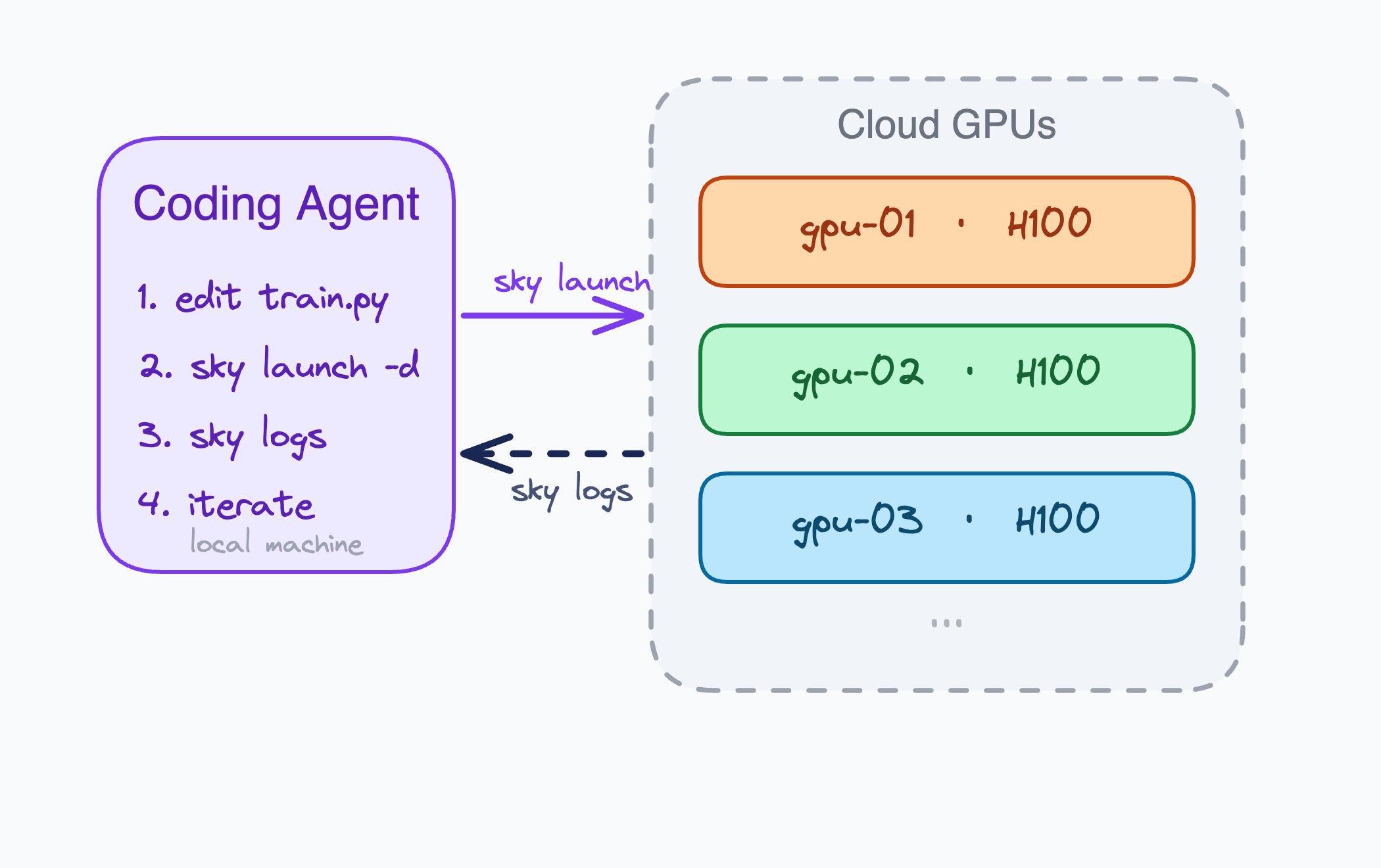
resources:
accelerators: {H100:1, H200:1}
infra: k8s
run: |
uv run train.py 2>&1 | tee run.log
再配合 sky launch 和 sky exec 这样的命令,agent 就能把原来“改代码—等待训练—读结果”的单线程流程,变成一个持续占满集群的流水线。这里真正值钱的,不只是 SkyPilot 把云和 Kubernetes 封装了,而是它把 agent 可支配的实验带宽 放大了。
当然,这不代表“AI 研究员已经来了”。这类实验仍然受很强的任务结构约束。autoresearch 的边界很清楚:只能改 train.py,目标函数固定,评估方式固定,训练时长也固定。换句话说,它现在更擅长的是一个被良好约束的局部优化问题,而不是开放式科学发现。你让它去重新定义研究问题、设计长期路线、判断哪条技术方向最值得押注,这还是另一回事。
但即便如此,我还是觉得这篇东西释放了一个很清晰的信号:未来 agent 的能力上限,不只由模型本身决定,也越来越由它能调度多少工具、多少算力、多少并行实验来决定。
过去我们总把 agent 看成一个聪明一点的执行器。现在更像是在看一套会自己扩展工作面的系统。模型负责判断,基础设施负责放大,二者一旦咬合起来,很多原本属于“高级工程直觉”的东西,就会开始被流程化、批量化、持续化。
这也是为什么我会把这篇文章归到算力,而不只是 agent。因为它真正讲的不是“Claude Code 多会写代码”,而是 当算力调度被交到 agent 手里,研究效率会变成一种基础设施能力。 以后大家拼的,未必只是模型智商,还有谁能给 agent 更宽的实验空间、更快的反馈回路、更便宜的试错成本。
这件事一旦成立,研究团队的瓶颈就不再只是人够不够聪明,而会越来越变成:你的 agent,到底能动用多大的机器阵地。