Google 把 Gemma 4 推到了一个更现实的位置:不是最强,而是最能落地的开源模型
Google 发布 Gemma 4,把“开源模型竞争”从单纯拼参数,往设备适配、代理工作流和商业可用许可上拉了一层。真正值得看的是,它开始认真争夺本地 AI 和开发者生态的入口。
来源参考: Google Blog
Google 这次发 Gemma 4,真正有意思的地方,不是它又做出一个“更强的模型”,而是它把开源模型这件事,重新往可部署、可商用、可嵌进真实设备的方向推了一步。
过去一年,很多开源模型的发布节奏都很像:先比榜单,再比参数,再比谁更接近闭源旗舰。但 Gemma 4 的信号没那么简单。Google 这次强调的是另一套话语:同样是模型竞争,重点已经从“谁最会聊天”,慢慢转向“谁更适合放进产品里跑”。

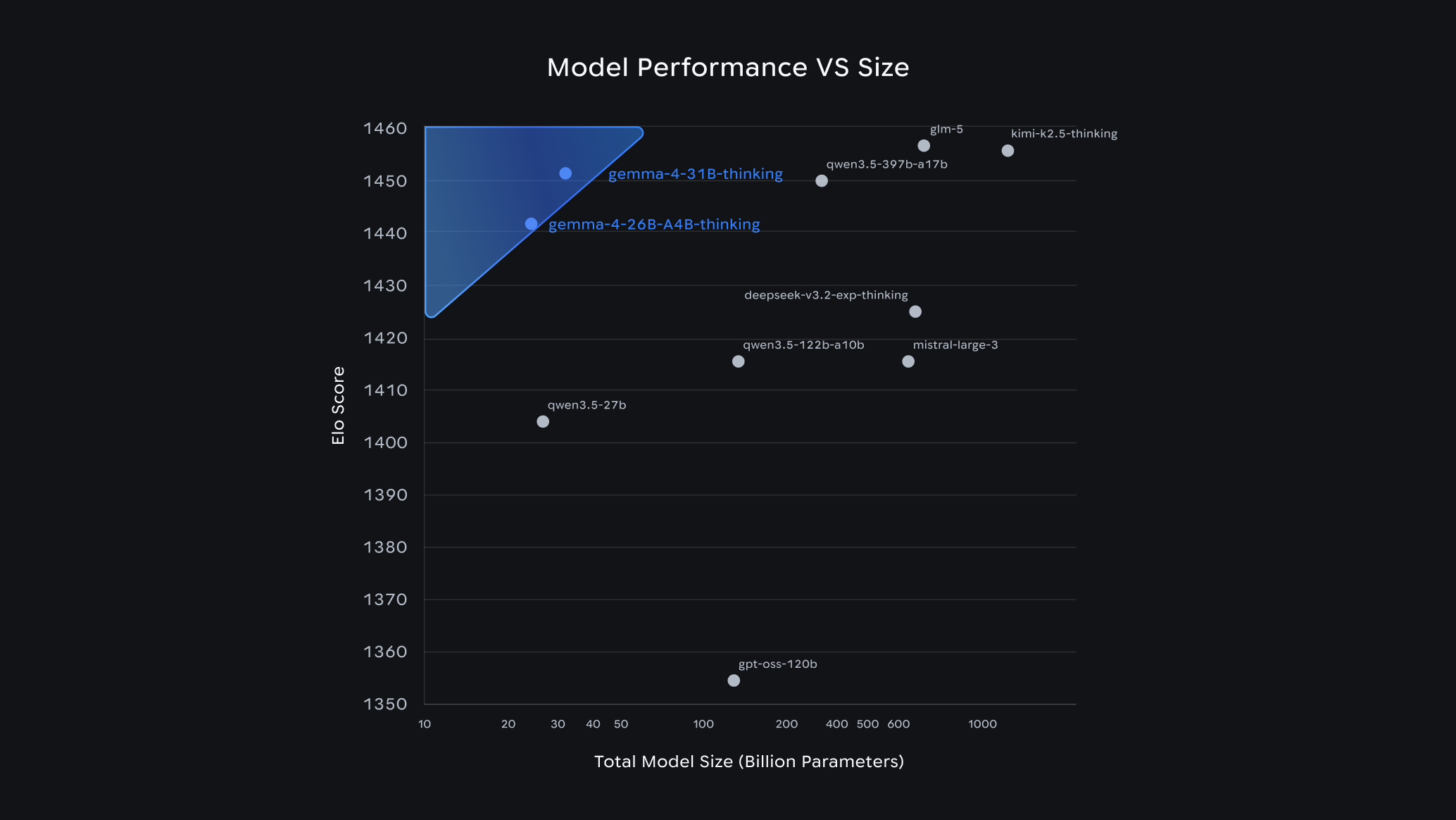
先看核心事实。Gemma 4 一次放出四个尺寸:E2B、E4B、26B MoE 和 31B Dense,覆盖从手机、IoT 设备到工作站和云端部署的不同场景。Google 给它打的几个关键词也很明确:高级推理、agentic workflows、代码生成、多模态、长上下文,以及 140 多种语言支持。
这里最值得注意的,不是功能表本身,而是这些能力的组合方式。Gemma 4 不是只想占一个“本地小模型”生态位,也不是只想做 Hugging Face 上的又一组权重文件。它想拿下的是开发者在本地 AI 工作流里的默认选项:能跑函数调用,能吐结构化 JSON,能处理图像和视频,能吃长上下文,还能在边缘设备上离线运行。这其实已经非常接近今天大家对“实用型 agent 模型”的要求了。
Google 还特意把两个卖点讲得很重。第一,是 intelligence-per-parameter。31B 模型在开放模型榜单上能打进前列,26B MoE 也在强调“用更少激活参数换更高速度”。这套叙事很聪明,因为它绕开了“你是不是全世界第一”这个很难长期赢的问题,转而强调“我是不是在现实硬件条件下最划算”。第二,是 Apache 2.0。这不是法律细节,而是市场信号。对很多企业和开发者来说,许可条款往往比 benchmark 更决定你能不能真拿去做产品。
这也解释了为什么 Gemma 4 的发布页里,几乎每一段都在强调工具链和落地生态:Hugging Face、Ollama、llama.cpp、vLLM、MLX、LM Studio、NVIDIA NIM、Android Studio、Google Cloud,基本是把本地到云端的常见入口全铺了一遍。它不是在单点突破,而是在抢“开发者第一次试、团队第一次接、产品第一次上线”那条路径上的每一个接触点。
从行业角度看,Gemma 4 的意义也挺直接。开源模型的竞争,已经不只是 Meta、Mistral、Qwen、DeepSeek 之间的参数赛跑,Google 现在明显也在认真下场,而且打法更偏平台型。Gemini 继续守住闭源旗舰和云服务,Gemma 则负责把开放模型、终端部署和开发者生态串起来。这种“双线作战”如果跑顺了,Google 在 AI 时代的入口控制力会更强,因为它不只提供最贵的那层能力,也开始覆盖最广的那层分发。
当然,风险和不确定性也很明显。首先,发布页里的很多优势仍然是 Google 自己定义的“最佳使用场景”,真正的开发者口碑,还要看社区几周后的实测反馈。其次,开源模型今天的竞争已经非常卷,单次发布很难长期占住心智,尤其是在中文生态和企业私有化部署场景里,Gemma 还要面对更本地化、响应更快的对手。再往下看,多模态、代理调用和端侧部署虽然都很性感,但真正把这些能力拼成稳定产品,难点从来都不在发布会,而在工程细节。
但即便如此,我还是觉得 Gemma 4 这次值得重视。它释放出的不是“Google 也有个开源模型了”这么简单的信息,而是 Google 开始把开源模型当成一个真正的产品层入口来经营。对开发者来说,这意味着本地 AI 的工具箱会更完整;对竞争对手来说,这意味着开源战场上的压力,接下来只会更大。